
AB kasutajate rollid
AB kasutaja > tavakasutaja, mis saab muuta, lisada, filtreerida ja otsida vastavalt vajadusele
Programmeerija > loob funktsioonid, protseduurid ja trigerid
DBA > AB administraator, kes tagab, et õiged kasutajad saavad oma õigused
AB projekteerija > loob tabeleid ja AB struktuuri
DBA liigid
Süsteemiadmin
AB arhitekt
AB analüütik
Data warehouse admin > хранилище данных
DBA eesmärkid
DBA on kaks peamist eesmärki:
- Kasutajate toetus ja ligipääsu jagamine ja seadistamine
- AB turvalisus ja jõudluse tagamine
AB turvalisus
Konfidentsiaalsus > confidentiality
GRANT role to user [identified by pwd] [with grant option];
REVOKE role from user;
Kättesaadavus > availability
Andmed me saame kätte õigel ajal ja õigel kasutajal
Terviklikkus > целостность, integrity
Usaldusväärne andmeallikas
| Risk | Ohutuse aspekt |
|---|---|
| Inimlikud vead | Konfidentsiaalsus, kättesaadavus, terviklikkus |
| Füüsilised vead (riistvara) | Kättesaadavus, terviklikkus |
| Operatsioonisüsteemi rikked | Konfidentsiaalsus, kättesaadavus, terviklikkus |
| Andmebaasisüsteemi rikked | Konfidentsiaalsus, kättesaadavus, terviklikkus |
Transaktsioonid
COMMIT – salvestab kõik transaktsiooni jooksul tehtud muudatused
ROLLBACK – tühistab kõik praeguse transaktsiooni jooksul tehtud muutused
ROLLFORWARD – taastab andmebaasi pärast riket, kasutades salvestatud toiminguid logist
Andmed
Data Mining – on protsess, mille käigus ekstraheeritakse suurtest andmekogudest olulisi mustreid, kõrvalekaldeid ja järeldusi.
Data Warehouse – on keskne andmehoidla, mis kogub, integreerib ja säilitab suuri koguseid struktureeritud ja poolstruktureeritud andmeid.
Mida tähendab
- GROUP BY – rühmitab samade väärtustega read kokkuvõtete ridadeks, näiteks “leia klientide arv igas riigis”.
- UNION ALL – Operaatorit kasutatakse kahe või enama SELECT-lause tulemuste kombinatsiooniks.
- GROUPING – kasutatakse ROLLUP, CUBE või GROUPING SETS poolt tagastatud nullväärtuste eristamiseks standardse nullväärtusest
- ROLLUP – laiendus, mis võimaldab arvutada mitme taseme vahesummasid määratud atribuutide rühma ulatuses
- CUBE – kasutatakse koos klausliga “GROUP BY”, et genereerida vahekokkuvõtteid ja kogusummasid mitmes mõõtmes ühe päringu abil
Erinevus ROLLUP ja CUBE – ROLLUP arvutab vahesummad ja kogusummad. CUBE võib arvutada vahesummad ja kogusummad kõigi rühmitamiskolonnide kombinatsioonide jaoks.
Võtid
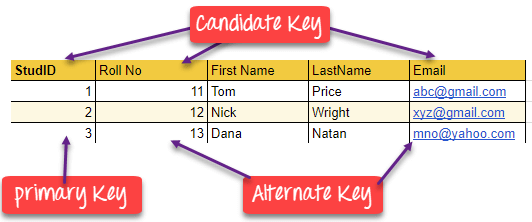
PRIMARY KEY / ALTERNATE KEY / CANDIDATE KEY
PRIMARY KEY on tabeli veerg või veergude rühm, mis identifitseerib tabeli iga rea üheselt. Primary key ei tohi olla dubleeritud, mis tähendab, et sama väärtus ei tohi tabelis esineda rohkem kui üks kord. Tabelis ei tohi olla rohkem kui üks primary key.
ALTERNATE KEY on tabeli veerg või veergude rühm, mis identifitseerib tabeli iga rea üheselt. Tabelil võib olla mitu primary key valikut, kuid primary key saab määrata ainult ühe. Kõiki võtmeid, mis ei ole primary key, nimetatakse alternate key.
CANDIDATE KEY on atribuutide kogum, mis identifitseerib tabelis olevad tuplid üheselt. Candidate key on super key, millel ei ole korduvaid atribuute. Primary key tuleks valida candidate key hulgast. Igal tabelil peab olema vähemalt üks candidate key. Tabelil võib olla mitu candidate key, kuid ainult üks primary key.
- Selles näites on StudID esmane võti
- Kuna StudID on primary key, muutuvad Roll No ja Email alternate key
- Antud tabelis on StudID, RollNo ja Email candidate key, mis aitavad meil tabelis õpilase andmeid üheselt identifitseerida
CREATE TABLE Students (
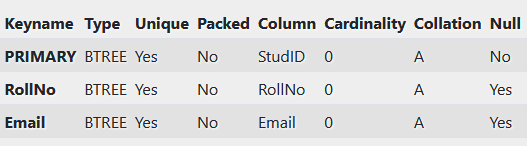
StudID INT PRIMARY KEY, -- Primary key, Candidate key
RollNo INT UNIQUE, -- Alternate key, Candidate key
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(100) UNIQUE -- Alternate key, Candidate key
);
Students struktuur:
SIMPLE KEY / FOREIGN KEY
SIMPLE KEY on lihtsalt üks veerg, mis võimaldab rida üheselt identifitseerida. Seega on iga tabelis olev veerg, mis võimaldab rida üheselt identifitseerida, simple key. Seda nimetatakse Simple key, kuna see on lihtne selles mõttes, et see koosneb ainult ühest veerust ja mitte millestki muust.
FOREIGN KEY on veerg, mis loob seose kahe tabeli vahel. Foreign key eesmärk on säilitada andmete terviklikkus ja võimaldada navigeerimist kahe erineva entiteedi vahel. See toimib kahe tabeli vahelise ristviitena, kuna viitab teise tabeli primary key.
Loome tabelid foreign key jaoks ja simple key näide:
-- Table Departments
CREATE TABLE Departments (
DeptCode INT PRIMARY KEY -- << Simple key
DeptName VARCHAR(50)
);
-- Table Teachers
CREATE TABLE Teachers (
TeacherID INT PRIMARY KEY,
DeptCode INT,
Fname VARCHAR(50),
Lname VARCHAR(50),
);
Selles näites on meil kaks tabelit: õpetajad ja osakonnad koolis. Siiski pole võimalik näha, milline otsing toimib millises osakonnas.
Selles koodis saame lisada foreign key Deptcode õpetaja nimele ja luua seose kahe tabeli vahel.
ALTER TABLE Teachers
ADD CONSTRAINT fk_Teachers_Departments
FOREIGN KEY (DeptCode) REFERENCES Departments(DeptCode) -- << Foreign key
Teachers struktuur:

COMPOUND KEY / COMPOSITE KEY
COMPOUND KEY on kaks või enam atribuuti, mis võimaldavad teil kindlalt ära tunda konkreetse kirje. On võimalik, et iga veerg ei ole andmebaasis iseenesest unikaalne. Kuid kombineerituna teise veeruga või veergudega muutub Compound key kombinatsioon unikaalseks. Compound key eesmärk andmebaasis on kindlalt identifitseerida iga kirje tabelis.
COMPOSITE KEY on kahe või enama veeru kombinatsioon, mis identifitseerib tabelis unikaalselt ridu. Veergude kombinatsioon tagab unikaalsuse, kuigi individuaalselt unikaalsust ei tagata. Seetõttu kombineeritakse need, et identifitseerida tabelis unikaalselt kirjed.
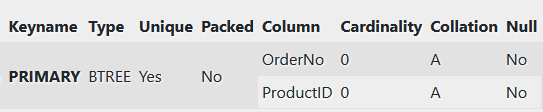
Selles näites ei saa OrderNo ja ProductID olla primary key, kuna need ei identifitseeri kirjet üheselt. Siiski võiks kasutada Order ID ja Product ID compound key/composite key, kuna see identifitseerib iga kirje üheselt.
CREATE TABLE Orders (
OrderNo INT,
ProductID VARCHAR(20),
ProductName VARCHAR(50),
Quantity INT,
PRIMARY KEY (OrderNo, ProductID) -- << Compound key, composite key
);
Erinevus compound ja composite key vahel on selles, et compound key mis tahes osa võib olla foreign key, kuid composite key võib olla või mitte olla foreign key osa.
Orders struktuur:
SUPER KEY
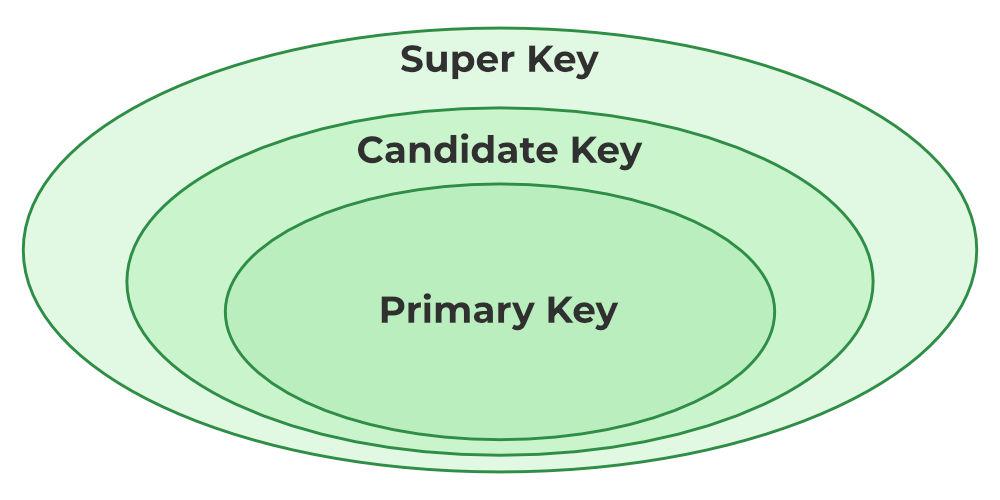
SUPER KEY on ühe või mitme veeru kogum, mis võimaldab kirjet üheselt identifitseerida, on tuntud kui Super key. See võib sisaldada lisatunnuseid, mis ei ole unikaalsuse seisukohalt olulised, kuid mis siiski identifitseerivad rea üheselt. Näiteks STUD_NO, (STUD_NO, STUD_NAME) jne.
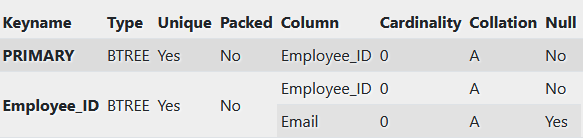
Vaatame tabelit Employees:
CREATE TABLE Employees (
Employee_ID INT PRIMARY KEY,
Name VARCHAR(50),
Department VARCHAR(50),
Email VARCHAR(100),
UNIQUE (Employee_ID, Email) -- << Super key
);
Selles näites:
- Employee_ID identifitseerib tabelis iga rea unikaalselt.
- Kõik atribuudikombinatsioonid, mis sisaldavad Employee_ID-d, on samuti Super key, kuna Employee_ID üksi on unikaalsuse tagamiseks piisav.
Employees struktuur:
UNIQUE KEY
UNIQUE KEY tagab, et kõik veeru või veergude rühma väärtused on kogu tabelis unikaalsed. Lisaks, kui unique key rakendatakse mitmele veerule korraga, peab iga nende veergude väärtuste kombinatsioon olema kogu tabelis unikaalne.
Teine omadus on see, et erinevalt primary key võivad need sisaldada NULL-väärtusi, mis võivad olla unikaalsed.
Vaatame näiteks tabelit nimega Student2:
CREATE TABLE Student2 (
id INT UNIQUE, -- << Unique key
name VARCHAR(60),
national_id BIGINT NOT NULL,
birth_date DATE,
enrollment_date DATE,
graduation_date DATE
);
Student2 struktuur:

Allikad
- DBMS Keys: Candidate, Super, Primary, Foreign Key Types with Example – https://www.guru99.com/dbms-keys.html
- Keys in Relational Model – https://www.geeksforgeeks.org/dbms/types-of-keys-in-relational-model-candidate-super-primary-alternate-and-foreign
- Understanding MySQL Keys: MUL, PRI, and UNI Explained – https://www.baeldung.com/sql/mysql-keys-mul-pri-uni
- What is a simple key in a dbms? – https://www.programmerinterview.com/database-sql/simple-key-in-sql/